
Some basic statistical techniques for Product Managers
Introduction

Introduction
Data analysis is one of the main challenges that a Product Manager (PM) needs to face off. However it is very difficult to find PMs with enough analytical skills to solve even simple analytical problems. I’m not talking about KPIs and metrics definitions, since more of PMs feel comfortable defining the proper metrics to track the evolution of the features that are launched to production. My focus on this paper is rather on the basic statistical tools that PMs should have in their backpacks to avoid being fooled by the hidden devil who live behind the data.
The following sections describe the basic statistical tools that any PM should apply to make sure that the hypothesis are validated in a scientific way.
Descriptive Statistics
The first step when you start to dive deep into your data lake is getting a statistical description of your data sample. Of course, some basic intuitions can be extracted just launching an SQL query, but given that data samples are not very intuitive, in addition to the dangers of the confirmation bias, it is very worthwhile to display some very basic statistical analysis to double check that we won’t follow a wrong analytical path.
Summary statistics
Summary statistics are used to summarize a set of observations, in order to communicate the largest amount of information as simply as possible*. We will use the following metrics:
Count of rows
Arithmetic mean
Standard deviation
The sample minimum (smallest observation)
The lower quartile or first quartile (25%)
The median (the middle value) (50%)
The upper quartile or third quartile (75%)
The sample maximum (largest observation)
These metrics provide a clear understanding of the quality of your data, since allow you to go further the arithmetic mean. Arithmetic mean are quite useful to summarize your data, but at the same time is quite dangerous if it is used without the support of other additional measures like the standard deviation or the median. Remember, that the mean said that if I have two millions of euros and you have cero euros, each of us have one million of euros.
Quartiles, median, and standard deviation help us to check how trustable is the arithmetic mean and therefore, how stable is our data distribution in order to get conclusion or validate our hypothesis. High standard deviations regarding the arithmetic mean or a significant difference between the mean and the median can tell us that the mean is masking the real behaviour behind our data.
Python recipe for Summary statistics
Getting statistical summaries with Pandas (the python library for advanced data analysis) is very straightforward.
import pandas as pd
df = pd.read_csv("your_file", sep=";", names = ["column_1","column_2"])df.describe('column_to_describe')Output

Line Plots
Once you have a numerical summary of your data sample, the next step is moving forward with some very basic data visualization techniques. Lines plots are quite useful, specially when you are dealing with a temporal dimension. I will provide more detail in another tutorial about how to work with Time Series but just a basic line plot can help you a lot to understand how your data sample behave across the time.
Python recipe for line plots
Plotting your data with pandas is again quite simple
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("your_file", sep=";", names = ["column_1","column_2"])df.plot(x='column_to_plot_x_axis', y='column_to_plot_y_axis', figsize=(18,4))
plt.show()Output

Shape of the distribution
Plotting the probability distribution of your data sample is, by far, the simplest visualization technique to detect anomalies in your data.
When we are making decisions based on the arithmetic mean we assume that the data sample is a perfect normal distribution, which in practice is not very realistic. In the real world most of data distributions have outliers and local tendencies that need to be analysed to really understand what is going on with our data.
In a probability distribution plot y’s axis represent the probability (actually is a density function, but let’s keep it simple) of getting the values represented in the x’s axis, which provides a clear view of the central tendency of the distribution, which corresponds to the mean, but also provides a nice view of other significant values in the distribution which match with other less common but still significant events.
Below, we have an example where we can see that, further the mean of the distribution, we have a bunch of values that need to be analysed in a separated way.

Python recipe for Probability Distribution
Probability distribution can be plotted using pandas plot function just setting the kind parameter to kde (Kernel Density Estimation) which is a non-parametric way to estimate the probability density function.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("your_file", sep=";", names = ["column_1","column_2"])
df.plot(y='column_to_plot', kind='kde', figsize=(18,4))
plt.show()Output

Outliers analysis
Outliers analysis is important for data cleaning and anomalies detection.
To properly detect and remove outliers we can use Box and Whisker plots and Z-score.
Box and Whisker plots
Box and Whiskers or Box plot provides a very nice visual representation of the numerical summary statistics, including those values that are good candidates to be labeled as outliers.

Python Recipe for Box and Whisker plots
Box plots are also available in the wrapper that pandas implements around matplotlib.
import pandas as pd
df = pd.read_csv("your_file", sep=";", names = ["column_1","column_2"])
df.boxplot(column=['column_to_plot'])
plt.show()Output

Z score
Outliers can be removed using z-score which is related with the number of standard deviations from the mean. Usually every value outside three standard deviations can be considered as an outlier.
Python Recipe for Z score
The following code reproduce an example to implement a function to remove outliers from a given list of columns in a dataframe.
import pandas as pd
from scipy.stats import zscore
def remove_outliers(df, columns):
for column in columns:
df = df[(np.abs(zscore(df[column])) < 3)]
return df
df = pd.read_csv("your_file", sep=";", names = ["column_1","column_2"])
df = remove_outliers(df,['column_to_remove_outliers'])Measure of statistical dependence
If more than one variable is measured than correlation coefficient can be calculated in order to understand the statistical relationship between the variables. Getting the correlation between two or more variables can help us to understand the interaction between the variables and it is the first step to carry out statistical inference and predict the future behaviour of the variables in the sample.
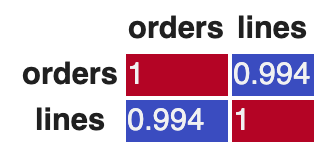
Pearson correlation measure
Pearson correlation is a common correlation measure that can be used to figure out how is the relationship between several variables. This measure goes from -1 to +1 where 0 means not correlation at all, positive numbers mean positive correlation and negative values show an inverse correlation between the variables. Correlations above 0.5 can very very useful for prediction tasks.
Python Recipe for correlation
The correlation measure is also included out-of-the-box in pandas.
import pandas as pd
df = pd.read_csv("your_file", sep=";", names = ["column_1","column_2"])
df.corr()Output
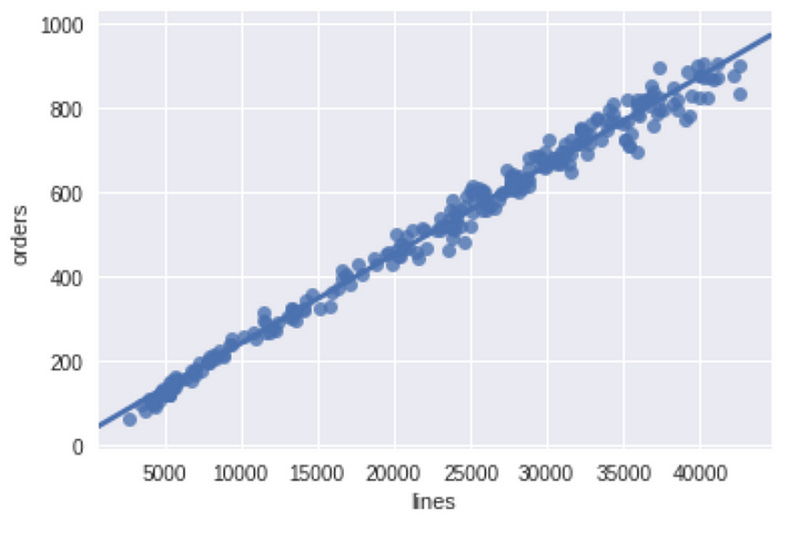
Regression plot
Having a high correlation value is a very good starting point. However, drawing a scatter chart is also a good way to figure out how good the correlation is, since a high correlation could hide a trap because the nature of the outliers or the data distribution. You can get more information about this statistical behaviour at Anscombe’s quartet.
To avoid this problem you can plot the regression plot to make sure that your correlations looks OK further the number that you are getting from the correlation coefficient.
Python recipe for regression plot
import pandas as pd
import seaborn as sns
df = pd.read_csv("your_file", sep=";", names = ["column_1","column_2"])
sns.regplot(x="column_1", y="column_2", data=df)Output
Conclusion
PMs need to deal with data in a daily basis, of course, a PM is not a data scientist or an statistician, however, given that PMs make data-driven decisions everyday it is very important to become fluent with some very basic statistical techniques in order to make rock-solid data-driven decisions and avoid being fooled by the complexity that exists behind every data sample.